Распределение Пирсона (распределение хи-квадрат). Классические методы статистики: критерий хи-квадрат
В настоящей заметке χ 2 -распределение используется для проверки согласованности набора данных с фиксированным распределением вероятностей. В критерии согласия часто ты, принадлежащие определенной категории, сравниваются с частотами, которые являются теоретически ожидаемыми, если бы данные действительно имели указанное распределение.
Проверка с помощью критерия согласия χ 2 выполняется в несколько этапов. Во-первых, определяется конкретное распределение вероятностей, которое сравнивается с исходными данными. Во-вторых, выдвигается гипотеза о параметрах выбранного распределения вероятностей (например, о ее математическом ожидании) или проводится их оценка. В-третьих, на основе теоретического распределения определяется теоретическая вероятность, соответствующая каждой категории. В заключение, для проверки согласованности данных и распределения применяется тестовая χ 2 -статистика:
где f 0 - наблюдаемая частота, f е - теоретическая, или ожидаемая частота, k - количество категорий, оставшихся после объединения, р - количество оцениваемых параметров.
Скачать заметку в формате или , примеры в формате
Использование χ 2 -критерия согласия для распределения Пуассона

Для расчета по этой формуле в Excel удобно воспользоваться функцией =СУММПРОИЗВ() (рис. 1).
Для оценки параметра λ можно воспользоваться оценкой . Теоретическую частоту X успехов (Х = 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 и более), соответствующую параметру λ = 2,9 можно определить с помощью функции =ПУАССОН.РАСП(Х;;ЛОЖЬ). Умножив пуассоновскую вероятность на объем выборки n , получим теоретическую частоту f e (рис. 2).

Рис. 2. Фактические и теоретические частоты прибытий в минуту
Как следует из рис. 2, теоретическая частота девяти и более прибытий не превосходит 1,0. Для того чтобы каждая категория содержала частоту, равную 1,0 или большему числу, категорию «9 и более» следует объединить с категорией «8». То есть, остается девять категорий (0, 1, 2, 3, 4, 5, 6, 7, 8 и более). Поскольку математическое ожидание распределения Пуассона определяется на основе выборочных данных, количество степеней свободы равно k – р – 1 = 9 – 1 – 1 = 7. Используя уровень значимости, равный 0,05 находим критическое значение χ 2 -статистики, имеющей 7 степеней свободы по формуле =ХИ2.ОБР(1-0,05;7) = 14,067. Решающее правило формулируется следующим образом: гипотеза Н 0 отклоняется, если χ 2 > 14,067, в противном случае гипотеза Н 0 не отклоняется.
Для расчета χ 2 воспользуемся формулой (1) (рис. 3).

Рис. 3. Расчет χ 2 -критерия согласия для распределения Пуассона
Так как χ 2 = 2,277 < 14,067, следует, что гипотезу Н 0 отклонять нельзя. Иначе говоря, у нас нет оснований утверждать, что прибытие клиентов в банк не подчиняется распределению Пуассона.
Применение χ 2 -критерия согласия для нормального распределения
В предыдущих заметках при проверке гипотез о числовых переменных использовалось предположение о том, что исследуемая генеральная совокупность имеет нормальное распределение. Для проверки этого предположения можно применять графические средства, например, блочную диаграмму или график нормального распределения (подробнее см. ). При больших объемах выборок для проверки этих предположений можно использовать χ 2 -критерий согласия для нормального распределения.
Рассмотрим в качестве примера данные о 5-летней доходности 158 инвестиционных фондов (рис. 4). Предположим, требуется поверить, имеют ли эти данные нормальное распределение. Нулевая и альтернативная гипотезы формулируются следующим образом: Н 0 : 5-летняя доходность подчиняется нормальному распределению, Н 1 : 5-летняя доходность не подчиняется нормальному распределению. Нормальное распределение имеет два параметра - математическое ожидание μ и стандартное отклонение σ, которые можно оценить на основе выборочных данных. В данном случае = 10,149 и S = 4,773.

Рис. 4. Упорядоченный массив, содержащий данные о пятилетней среднегодовой доходности 158 фондов
Данные о доходности фондов можно сгруппировать, разбив, например на классы (интервалы) шириной 5% (рис. 5).

Рис. 5. Распределение частот для пятилетней среднегодовой доходности 158 фондов
Поскольку нормальное распределение является непрерывным, необходимо определить площадь фигур, ограниченных кривой нормального распределения и границами каждого интервала. Кроме того, поскольку нормальное распределение теоретически изменяется от –∞ до +∞, необходимо учитывать площадь фигур, выходящих за пределы классов. Итак, площадь, лежащая под нормальной кривой слева от точки –10, равна площади фигуры, лежащей под стандартизованной нормальной кривой слева от величины Z, равной
Z = (–10 – 10,149) / 4,773 = –4,22
Площадь фигуры, лежащей под стандартизованной нормальной кривой слева от величины Z = –4,22 определяется по формуле =НОРМ.РАСП(-10;10,149;4,773;ИСТИНА) и приближенно равна 0,00001. Для того чтобы вычислить площадь фигуры, лежащей под нормальной кривой между точками –10 и –5, сначала необходимо вычислить площадь фигуры, лежащей слева от точки –5: =НОРМ.РАСП(-5;10,149;4,773;ИСТИНА) = 0,00075. Итак, площадь фигуры, лежащей под нормальной кривой между точками –10 и –5, равна 0,00075 – 0,00001 = 0,00074. Аналогично можно вычислить площадь фигуры, ограниченной границами каждого класса (рис. 6).

Рис. 6. Площади и ожидаемые частоты для каждого класса 5-летней доходности
Видно, что теоретические частоты в четырех крайних классах (два минимальных и два максимальных) меньше 1, поэтому проведем объединение классов, как показано на рис 7.

Рис. 7. Вычисления, связанные с применением χ 2 -критерия согласия для нормального распределения
Используем χ 2 -критерий согласия данных с нормальным распределением с помощью формулы (1). В нашем примере после объединения остаются шесть классов. Поскольку математическое ожидание и стандартное отклонение оцениваются на основе выборочных данных, количество степеней свободы равно k – p – 1 = 6 – 2 – 1 = 3. Используя уровень значимости, равный 0,05, находим, что критическое значение χ 2 -статистики, имеющее три степени свободы =ХИ2.ОБР(1-0,05;F3) = 7,815. Вычисления, связанные с применением χ 2 -критерия согласия, приведены на рис. 7.
Видно, что χ 2 -статистика = 3,964 < χ U 2 7,815, следовательно гипотезу Н 0 отклонять нельзя. Иначе говоря, у нас нет оснований утверждать, что 5-летняя доходность инвестиционных фондов, ориентированных на быстрый рост, не подчиняется нормальному распределению.
В нескольких последних заметках рассмотрены разные подходы к анализу категорийных данных. Описаны методы проверки гипотез о категорийных данных, полученных на основе анализа двух или нескольких независимых выборок. Кроме критериев «хи-квадрат», рассмотрены непараметрические процедуры. Описан ранговый критерий Уилкоксона, который используется в ситуациях, когда не выполняются условия применения t -критерия для поверки гипотезы о равенстве математических ожиданий двух независимых групп, а также критерий Крускала-Уоллиса, который является альтернативой однофакторному дисперсионному анализу (рис. 8).

Рис. 8. Структурная схема методов проверки гипотез о категорийных данных
Используются материалы книги Левин и др. Статистика для менеджеров. – М.: Вильямс, 2004. – с. 763–769
). Конкретная формулировка проверяемой гипотезы от случая к случаю будет варьировать.
В этом сообщении я опишу принцип работы критерия \(\chi^2\) на (гипотетическом) примере из иммунологии . Представим, что мы выполнили эксперимент по установлению эффективности подавления развития микробного заболевания при введении в организм соответствующих антител . Всего в эксперименте было задействовано 111 мышей, которых мы разделили на две группы, включающие 57 и 54 животных соответственно. Первой группе мышей сделали инъекции патогенных бактерий с последующим введением сыворотки крови, содержащей антитела против этих бактерий. Животные из второй группы служили контролем – им сделали только бактериальные инъекции. После некоторого времени инкубации оказалось, что 38 мышей погибли, а 73 выжили. Из погибших 13 принадлежали первой группе, а 25 – ко второй (контрольной). Проверяемую в этом эксперименте нулевую гипотезу можно сформулировать так: введение сыворотки с антителами не оказывает никакого влияния на выживаемость мышей. Иными словами, мы утверждаем, что наблюдаемые различия в выживаемости мышей (77.2% в первой группе против 53.7% во второй группе) совершенно случайны и не связаны с действием антител.
Полученные в эксперименте данные можно представить в виде таблицы:
Всего |
|||
Бактерии + сыворотка |
|||
Только бактерии |
|||
Всего |
Таблицы, подобные приведенной, называют таблицами сопряженности . В рассматриваемом примере таблица имеет размерность 2х2: есть два класса объектов («Бактерии + сыворотка» и «Только бактерии»), которые исследуются по двум признакам ("Погибло" и "Выжило"). Это простейший случай таблицы сопряженности: безусловно, и количество исследуемых классов, и количество признаков может быть бóльшим.
Для проверки сформулированной выше нулевой гипотезы нам необходимо знать, какова была бы ситуация, если бы антитела действительно не оказывали никакого действия на выживаемость мышей. Другими словами, нужно рассчитать ожидаемые частоты для соответствующих ячеек таблицы сопряженности. Как это сделать? В эксперименте всего погибло 38 мышей, что составляет 34.2% от общего числа задействованных животных. Если введение антител не влияет на выживаемость мышей, в обеих экспериментальных группах должен наблюдаться одинаковый процент смертности, а именно 34.2%. Рассчитав, сколько составляет 34.2% от 57 и 54, получим 19.5 и 18.5. Это и есть ожидаемые величины смертности в наших экспериментальных группах. Аналогичным образом рассчитываются и ожидаемые величины выживаемости: поскольку всего выжили 73 мыши, или 65.8% от общего их числа, то ожидаемые частоты выживаемости составят 37.5 и 35.5. Составим новую таблицу сопряженности, теперь уже с ожидаемыми частотами:
Погибшие |
Выжившие |
Всего |
|
Бактерии + сыворотка |
|||
Только бактерии |
|||
Всего |
Как видим, ожидаемые частоты довольно сильно отличаются от наблюдаемых, т.е. введение антител, похоже, все-таки оказывает влияние на выживаемость мышей, зараженных патогенным микроорганизмом. Это впечатление мы можем выразить количественно при помощи критерия согласия Пирсона \(\chi^2\):
\[\chi^2 = \sum_{}\frac{(f_o - f_e)^2}{f_e},\]
где \(f_o\) и \(f_e\) - наблюдаемые и ожидаемые частоты соответственно. Суммирование производится по всем ячейкам таблицы. Так, для рассматриваемого примера имеем
\[\chi^2 = (13 – 19.5)^2/19.5 + (44 – 37.5)^2/37.5 + (25 – 18.5)^2/18.5 + (29 – 35.5)^2/35.5 = \]
Достаточно ли велико полученное значение \(\chi^2\), чтобы отклонить нулевую гипотезу? Для ответа на этот вопрос необходимо найти соответствующее критическое значение критерия. Число степеней свободы для \(\chi^2\) рассчитывается как \(df = (R - 1)(C - 1)\), где \(R\) и \(C\) - количество строк и столбцов в таблице сопряженности. В нашем случае \(df = (2 -1)(2 - 1) = 1\). Зная число степеней свободы, мы теперь легко можем узнать критическое значение \(\chi^2\) при помощи стандартной R-функции qchisq() :
Таким образом, при одной степени свободы только в 5% случаев величина критерия \(\chi^2\) превышает 3.841. Полученное нами значение 6.79 значительно превышает это критического значение, что дает нам право отвергнуть нулевую гипотезу об отсутствии связи между введением антител и выживаемостью зараженных мышей. Отвергая эту гипотезу, мы рискуем ошибиться с вероятностью менее 5%.
Следует отметить, что приведенная выше формула для критерия \(\chi^2\) дает несколько завышенные значения при работе с таблицами сопряженности размером 2х2. Причина заключается в том, что распределение самого критерия \(\chi^2\) является непрерывным, тогда как частоты бинарных признаков ("погибло" / "выжило") по определению дискретны. В связи с этим при расчете критерия принято вводить т.н. поправку на непрерывность , или поправку Йетса :
\[\chi^2_Y = \sum_{}\frac{(|f_o - f_e| - 0.5)^2}{f_e}.\]
"s Chi-squared test with Yates" continuity correction data : mice X-squared = 5.7923 , df = 1 , p-value = 0.0161
Как видим, R автоматически применяет поправку Йетса на непрерывность (Pearson"s Chi-squared test with Yates" continuity correction ). Рассчитанное программой значение \(\chi^2\) составило 5.79213. Мы можем отклонить нулевую гипотезу об отсутствии эффекта антител, рискуя ошибиться с вероятностью чуть более 1% (p-value = 0.0161 ).
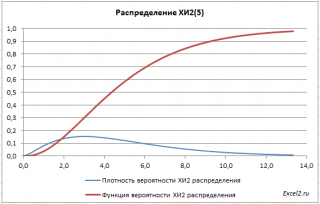
Рассмотрим Распределение ХИ-квадрат. С помощью функции MS EXCEL ХИ2.РАСП() построим графики функции распределения и плотности вероятности, поясним применение этого распределения для целей математической статистики.
Распределение ХИ-квадрат (Х 2 , ХИ2, англ. Chi - squared distribution ) применяется в различных методах математической статистики:
- при построении ;
- при ;
- при (согласуются ли эмпирические данные с нашим предположением о теоретической функции распределения или нет, англ. Goodness-of-fit)
- при (используется для определения связи между двумя категориальными переменными, англ. Chi-square test of association).
Определение : Если x 1 , x 2 , …, x n независимые случайные величины, распределенные по N(0;1), то распределение случайной величины Y=x 1 2 + x 2 2 +…+ x n 2 имеет распределение Х 2 с n степенями свободы.
Распределение Х 2 зависит от одного параметра, который называется степенью свободы (df , degrees of freedom ). Например, при построении число степеней свободы равно df=n-1, где n – размер выборки .
Плотность распределения
Х 2
выражается формулой:
Графики функций
Распределение Х 2 имеет несимметричную форму, равно n, равна 2n.
В файле примера на листе График приведены графики плотности распределения вероятности и интегральной функции распределения .
Полезное свойство ХИ2-распределения
Пусть x 1 , x 2 , …, x n независимые случайные величины, распределенные по нормальному закону
с одинаковыми параметрами μ и σ, а X cр
является арифметическим средним
этих величин x.
Тогда случайная величина y
равная
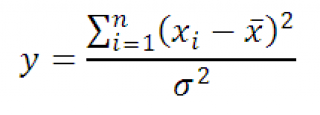
Имеет Х 2 -распределение с n-1 степенью свободы. Используя определение вышеуказанное выражение можно переписать следующим образом:

Следовательно, выборочное распределение статистики y, при выборке из нормального распределения , имеет Х 2 -распределение с n-1 степенью свободы.
Это свойство нам потребуется при . Т.к. дисперсия может быть только положительным числом, а Х 2 -распределение используется для его оценки, то y д.б. >0, как и указано в определении.
ХИ2-распределение в MS EXCEL
В MS EXCEL, начиная с версии 2010, для Х 2 -распределения имеется специальная функция ХИ2.РАСП() , английское название – CHISQ.DIST(), которая позволяет вычислить плотность вероятности (см. формулу выше) и (вероятность, что случайная величина Х, имеющая ХИ2 -распределение , примет значение меньше или равное х, P{X <= x}).
Примечание : Т.к. ХИ2-распределение является частным случаем , то формула =ГАММА.РАСП(x;n/2;2;ИСТИНА) для целого положительного n возвращает тот же результат, что и формула =ХИ2.РАСП(x;n; ИСТИНА) или =1-ХИ2.РАСП.ПХ(x;n) . А формула =ГАММА.РАСП(x;n/2;2;ЛОЖЬ) возвращает тот же результат, что и формула =ХИ2.РАСП(x;n; ЛОЖЬ) , т.е. плотность вероятности ХИ2-распределения.
Функция ХИ2.РАСП.ПХ()
возвращает функцию распределения
, точнее - правостороннюю вероятность, т.е. P{X > x}. Очевидно, что справедливо равенство
=ХИ2.РАСП.ПХ(x;n)+ ХИ2.РАСП(x;n;ИСТИНА)=1
т.к. первое слагаемое вычисляет вероятность P{X > x}, а второе P{X <= x}.
До MS EXCEL 2010 в EXCEL была только функция ХИ2РАСП() , которая позволяет вычислить правостороннюю вероятность, т.е. P{X > x}. Возможности новых функций MS EXCEL 2010 ХИ2.РАСП() и ХИ2.РАСП.ПХ() перекрывают возможности этой функции. Функция ХИ2РАСП() оставлена в MS EXCEL 2010 для совместимости.
ХИ2.РАСП() является единственной функцией, которая возвращает плотность вероятности ХИ2-распределения (третий аргумент должен быть равным ЛОЖЬ). Остальные функции возвращают интегральную функцию распределения , т.е. вероятность того, что случайная величина примет значение из указанного диапазона: P{X <= x}.
Вышеуказанные функции MS EXCEL приведены в .
Примеры
Найдем вероятность, что случайная величина Х примет значение меньше или равное заданного x : P{X <= x}. Это можно сделать несколькими функциями:
ХИ2.РАСП(x; n; ИСТИНА)
=1-ХИ2.РАСП.ПХ(x; n)
=1-ХИ2РАСП(x; n)
Функция ХИ2.РАСП.ПХ() возвращает вероятность P{X > x}, так называемую правостороннюю вероятность, поэтому, чтобы найти P{X <= x}, необходимо вычесть ее результат от 1.
Найдем вероятность, что случайная величина Х примет значение больше заданного x : P{X > x}. Это можно сделать несколькими функциями:
1-ХИ2.РАСП(x; n; ИСТИНА)
=ХИ2.РАСП.ПХ(x; n)
=ХИ2РАСП(x; n)
Обратная функция ХИ2-распределения
Обратная функция используется для вычисления альфа - , т.е. для вычисления значений x при заданной вероятности альфа , причем х должен удовлетворять выражению P{X <= x}=альфа .
Функция ХИ2.ОБР() используется для вычисления доверительных интервалов дисперсии нормального распределения .
Функция ХИ2.ОБР.ПХ() используется для вычисления , т.е. если в качестве аргумента функции указан уровень значимости, например 0,05, то функция вернет такое значение случайной величины х, для которого P{X>x}=0,05. В качестве сравнения: функция ХИ2.ОБР() вернет такое значение случайной величины х, для которого P{X<=x}=0,05.
В MS EXCEL 2007 и ранее вместо ХИ2.ОБР.ПХ() использовалась функция ХИ2ОБР() .
Вышеуказанные функции можно взаимозаменять, т.к. следующие формулы возвращают один и тот же результат:
=ХИ.ОБР(альфа;n)
=ХИ2.ОБР.ПХ(1-альфа;n)
=ХИ2ОБР(1- альфа;n)
Некоторые примеры расчетов приведены в файле примера на листе Функции .
Функции MS EXCEL, использующие ХИ2-распределение
Ниже приведено соответствие русских и английских названий функций:
ХИ2.РАСП.ПХ()
- англ. название CHISQ.DIST.RT, т.е. CHI-SQuared DISTribution Right Tail, the right-tailed Chi-square(d) distribution
ХИ2.ОБР()
- англ. название CHISQ.INV, т.е. CHI-SQuared distribution INVerse
ХИ2.ПХ.ОБР()
- англ. название CHISQ.INV.RT, т.е. CHI-SQuared distribution INVerse Right Tail
ХИ2РАСП()
- англ. название CHIDIST, функция эквивалентна CHISQ.DIST.RT
ХИ2ОБР()
- англ. название CHIINV, т.е. CHI-SQuared distribution INVerse
Оценка параметров распределения
Т.к. обычно ХИ2-распределение используется для целей математической статистики (вычисление доверительных интервалов, проверки гипотез и др.), и практически никогда для построения моделей реальных величин, то для этого распределения обсуждение оценки параметров распределения здесь не производится.
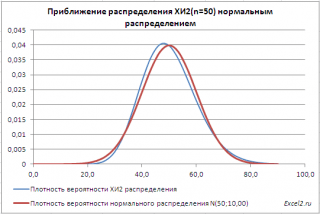
Приближение ХИ2-распределения нормальным распределением
При числе степеней свободы n>30 распределение Х 2
хорошо аппроксимируется нормальным распределением
со средним значением
μ=n и дисперсией σ
=2*n (см. файл примера лист Приближение
).
Использование этого критерия основано на применении такой меры (статистики) расхождения между теоретическим F(x) и эмпирическим распределением F* п (x) , которая приближенно подчиняется закону распределения χ 2 . Гипотеза Н 0 о согласованности распределений проверяется путем анализа распределения этой статистики. Применение критерия требует построения статистического ряда.
Итак, пусть выборка представлена статистическим рядом с количеством разрядов M . Наблюдаемая частота попаданий в i- й разряд n i . В соответствии с теоретическим законом распределения ожидаемая частота попаданий в i -й разряд составляет F i . Разность между наблюдаемой и ожидаемой частотой составит величину (n i – F i ). Для нахождения общей степени расхождения между F(x ) и F* п (x ) необходимо подсчитать взвешенную сумму квадратов разностей по всем разрядам статистического ряда
Величина χ 2 при неограниченном увеличении n имеет χ 2 -распределение (асимптотически распределена как χ 2). Это распределение зависит от числа степеней свободы k , т.е. количества независимых значений слагаемых в выражении (3.7). Число степеней свободы равно числу y минус число линейных связей, наложенных на выборку. Одна связь существует в силу того, что любая частота может быть вычислена по совокупности частот в оставшихся M –1 разрядах. Кроме того, если параметры распределения неизвестны заранее, то имеется еще одно ограничение, обусловленное подгонкой распределения к выборке. Если по выборке определяются S параметров распределения, то число степеней свободы составит k=M –S–1.
Область принятия гипотезы Н 0 определяется условием χ 2 < χ 2 (k;a) , где χ 2 (k;a) – критическая точка χ2-распределения с уровнем значимости a . Вероятность ошибки первого рода равна a , вероятность ошибки второго рода четко определить нельзя, потому что существует бесконечно большое множество различных способов несовпадения распределений. Мощность критерия зависит от количества разрядов и объема выборки. Критерий рекомендуется применять при n >200, допускается применение при n >40, именно при таких условиях критерий состоятелен (как правило, отвергает неверную нулевую гипотезу).
Алгоритм проверки по критерию
1. Построить гистограмму равновероятностным способом.
2. По виду гистограммы выдвинуть гипотезу
H 0: f (x ) = f 0(x ),
H 1: f (x ) f 0(x ),
где f 0(x ) - плотность вероятности гипотетического закона распределения (например, равномерного, экспоненциального, нормального).
Замечание . Гипотезу об экспоненциальном законе распределения можно выдвигать в том случае, если все числа в выборке положительные.
3. Вычислить значение критерия по формуле
 ,
,
где частота попадания в i -тый интервал;
pi - теоретическая вероятность попадания случайной величины в i - тый интервал при условии, что гипотеза H 0верна.
Формулы для расчета pi в случае экспоненциального, равномерного и нормального законов соответственно равны.
Экспоненциальный закон
![]() . (3.8)
. (3.8)
При этом A 1 = 0, Bm = +.
Равномерный закон
Нормальный закон
 . (3.10)
. (3.10)
При этом A 1 = -, B M = +.
Замечания . После вычисления всех вероятностей pi проверить, выполняется ли контрольное соотношение

Функция Ф(х )- нечетная. Ф(+) = 1.
4. Из таблицы " Хи-квадрат" Приложения выбирается значение , где - заданный уровень значимости (= 0,05 или = 0,01), а k - число степеней свободы, определяемое по формуле
k = M - 1 - S .
Здесь S - число параметров, от которых зависит выбранный гипотезой H 0закон распределения. Значения S для равномерного закона равно 2, для экспоненциального - 1, для нормального - 2.
5. Если , то гипотеза H 0отклоняется. В противном случае нет оснований ее отклонить: с вероятностью 1 - она верна, а с вероятностью - неверна, но величина неизвестна.
Пример3 . 1. С помощью критерия 2выдвинуть и проверить гипотезу о законе распределения случайной величины X , вариационный ряд, интервальные таблицы и гистограммы распределения которой приведены в примере 1.2. Уровень значимости равен 0,05.
Решение . По виду гистограмм выдвигаем гипотезу о том, что случайная величина X распределена по нормальному закону:
H 0: f (x ) = N (m ,);
H 1: f (x ) N (m ,).
Значение критерия вычисляем по формуле.
В практике биологических исследований часто бывает необходимо проверить ту или иную гипотезу, т. е. выяснить, насколько полученный экспериментатором фактический материал подтверждает теоретическое предположение, насколько анализируемые данные совпадают с теоретически ожидаемыми. Возникает задача статистической оценки разницы между фактическими данными и теоретическим ожиданием, установления того, в каких случаях и с какой степенью вероятности можно считать эту разницу достоверной и, наоборот, когда ее следует считать несущественной, незначимой, находящейся в пределах случайности. В последнем случае сохраняется гипотеза, на основе которой рассчитаны теоретически ожидаемые данные или показатели. Таким вариационно-статистическим приемом проверки гипотезы служит метод хи-квадрат (χ 2). Этот показатель часто называют «критерием соответствия» или «критерием согласия» Пирсона. С его помощью можно с той или иной вероятностью судить о степени соответствия эмпирически полученных данных теоретически ожидаемым.
С формальных позиций сравниваются два вариационных ряда, две совокупности: одна – эмпирическое распределение, другая представляет собой выборку с теми же параметрами (n , M , S и др.), что и эмпирическая, но ее частотное распределение построено в точном соответствии с выбранным теоретическим законом (нормальным, Пуассона, биномиальным и др.), которому предположительно подчиняется поведение изучаемой случайной величины.
В общем виде формула критерия соответствия может быть записана следующим образом:
где a – фактическая частота наблюдений,
A – теоретически ожидаемая частота для данного класса.
Нулевая гипотеза предполагает, что достоверных различий между сравниваемыми распределениями нет. Для оценки существенности этих различий следует обратиться к специальной таблице критических значений хи-квадрат (табл. 9П ) и, сравнив вычисленную величину χ 2 с табличной, решить, достоверно или не достоверно отклоняется эмпирическое распределение от теоретического. Тем самым гипотеза об отсутствии этих различий будет либо опровергнута, либо оставлена в силе. Если вычисленная величина χ 2 равна или превышает табличную χ ² (α , df ) , решают, что эмпирическое распределение от теоретического отличается достоверно. Тем самым гипотеза об отсутствии этих различий будет опровергнута. Если же χ ² < χ ² (α , df ) , нулевая гипотеза остается в силе. Обычно принято считать допустимым уровень значимости α = 0.05, т. к. в этом случае остается только 5% шансов, что нулевая гипотеза правильна и, следовательно, есть достаточно оснований (95%), чтобы от нее отказаться.
Определенную проблему составляет правильное определение числа степеней свободы (df ), для которых из таблицы берут значения критерия. Для определения числа степеней свободы из общего числа классов k нужно вычесть число ограничений (т. е. число параметров, использованных для расчета теоретических частот).
В зависимости от типа распределения изучаемого признака формула для расчета числа степеней свободы будет меняться. Для альтернативного распределения (k = 2) в расчетах участвует только один параметр (объем выборки), следовательно, число степеней свободы составляет df = k −1=2−1=1. Для полиномиального распределения формула аналогична: df = k −1. Для проверки соответствия вариационного ряда распределению Пуассона используются уже два параметра – объем выборки и среднее значение (численно совпадающее с дисперсией); число степеней свободы df = k −2. При проверке соответствия эмпирического распределения вариант нормальному или биномиальному закону число степеней свободы берется как число фактических классов минус три условия построения рядов – объем выборки, средняя и дисперсия, df = k −3. Сразу стоит отметить, что критерий χ² работает только для выборок объемом не менее 25 вариант , а частоты отдельных классов должны быть не ниже 4 .
Вначале проиллюстрируем применение критерия хи-квадрат на примере анализа альтернативной изменчивости . В одном из опытов по изучению наследственности у томатов было обнаружено 3629 красных и 1176 желтых плодов. Теоретическое соотношение частот при расщеплении признаков во втором гибридном поколении должно быть 3:1 (75% к 25%). Выполняется ли оно? Иными словами, взята ли данная выборка из той генеральной совокупности, в которой соотношение частот 3:1 или 0.75:0.25?
Сформируем таблицу (табл. 4), заполнив значениями эмпирических частот и результатами расчета теоретических частот по формуле:
А = n∙p,
где p – теоретические частости (доли вариант данного типа),
n – объем выборки.
Например, A 2 = n∙p 2 = 4805∙0.25 = 1201.25 ≈ 1201.






